

Chapter 1: Spark Basics¶
Learning Objectives¶
Understand what Apache Spark is.
Understand distributed data vs non-distributed data.
Understand how distributed data is stored in spark.
Overview of spark cluster.
Understand the working of spark cluster.
Chapter Outline¶
1. What is Apache Spark?¶
Apache Spark is a unified analytics engine for large-scale data processing. It consists of various modules as shown in the diagram below
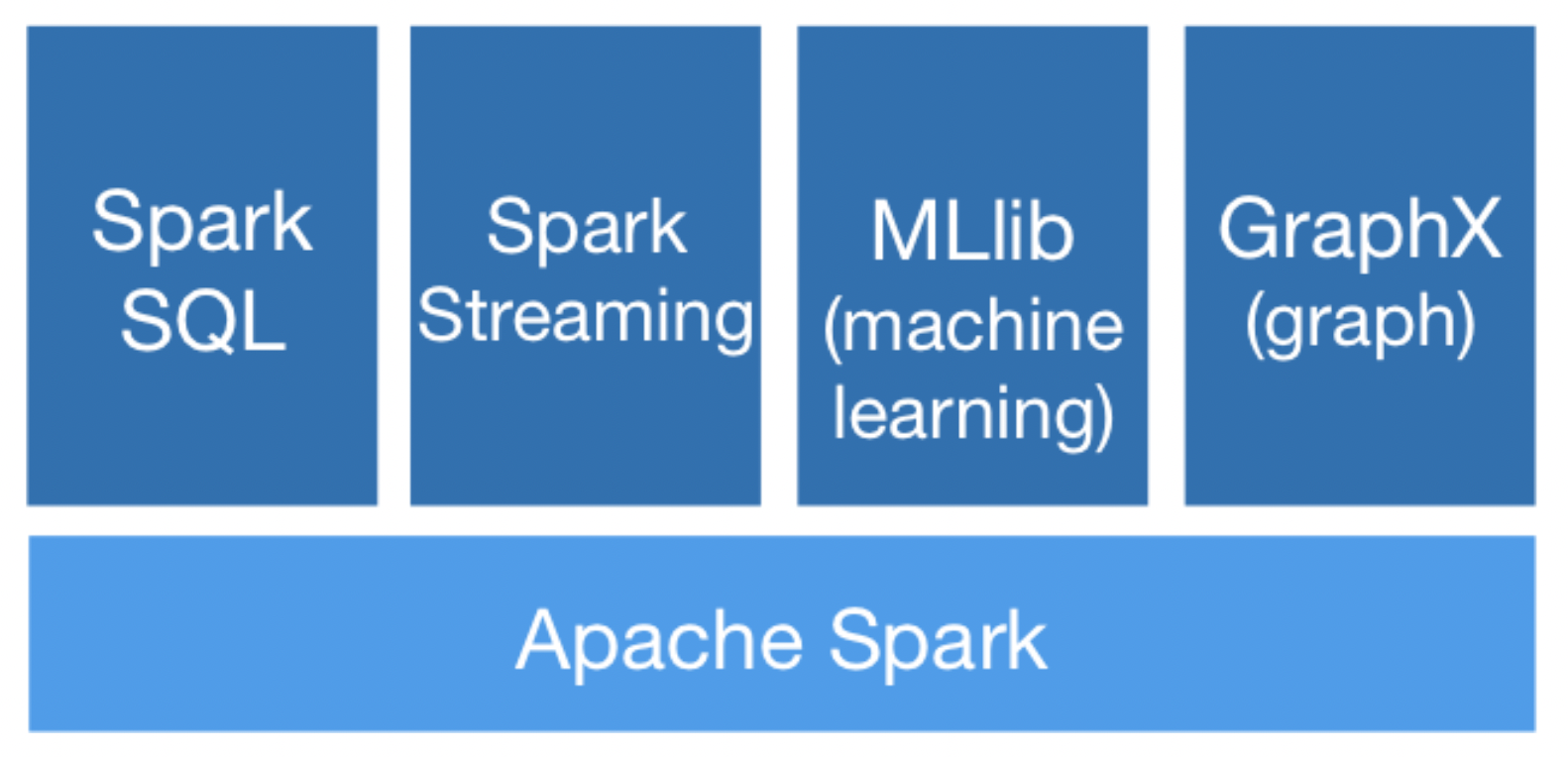
Spark’s Key Components
Spark Core— The general execution engine of the Spark platform, Spark Core contains various components for functions such as task scheduling, memory management, fault recovery, etc. Spark’s application program interface (API) that defines Resilient Distributed Datasets (RDDs) also resides in Spark Core. Thanks to RDDs—which can be thought of as a collection of items distributed across a vast number of compute nodes operating in parallel—Spark is able to draw on Hadoop clusters for stored data and process that data in-memory at unprecedented speeds, allowing data to be explored interactively in real-time.
Spark SQL—Big data consists of structured and unstructured data, each of which is queried differently. Spark SQL provides an SQL interface to Spark that allows developers to co-mingle SQL queries of structured data with the programmatic manipulations of unstructured data supported by RDDs, all within a single application. This ability to combine SQL with complex analytics makes Spark SQL a powerful open source tool for the data warehouse.
Spark Streaming—This Spark component enables analysts to process live streams of data, such as log files generated by production web servers, and live video and Stock Market feed. By providing an API for manipulating data streams that is a close match to Spark Core’s RDD API, Spark Streaming makes it easy for programmers to navigate between applications that process data stored in memory, on disk, or as it arrives in real time.
MLlib—Spark comes with an integrated framework for performing advanced analytics. Among the components found in this framework is Spark’s scalable Machine Learning Library (MLlib). The MLlib contains common machine learning (ML) functionality and provides a varied array of machine learning algorithms such as classification, regression, clustering, and collaborative filtering and model evaluation, and more. Spark and MLlib are set to run on a Hadoop 2.0 cluster without any pre-installation.
GraphX—Also found in Spark’s integrated framework is GraphX, a library of common graph algorithms and operators for manipulating graphs and performing graph-parallel computations. Extending the Spark RDD and API, GraphX allows users to create directed graphs with arbitrary properties attached to each vertex and edge. GraphX is best used for analytics on static graphs, such as Facebook’s Friend Graph that helps to uncover patterns that exist within social network connections.
Apache Spark is one of the largest open source communities in big data. With the flexibility and scalability to deliver real-time processing, plus the ability to constantly evolve through open source contributions, Apache Spark is on its way to achieving rock star status as a premiere big data tool.
Benefits:
Speed : Run workloads 100x faster.
Ease of Use : Write applications quickly in Java, Scala, Python, R, and SQL.
Generality : Combine SQL, streaming, and complex analytics.
Runs Everywhere : Spark runs on Hadoop, Apache Mesos, Kubernetes, standalone, or in the cloud. It can access diverse data sources

2. What is distributed data?¶
To answer this question, let us first understand how a non-distributed data look like. Lets us assume that a table consisting of just 3 records is stored on mySQL RDBMS in Linux.
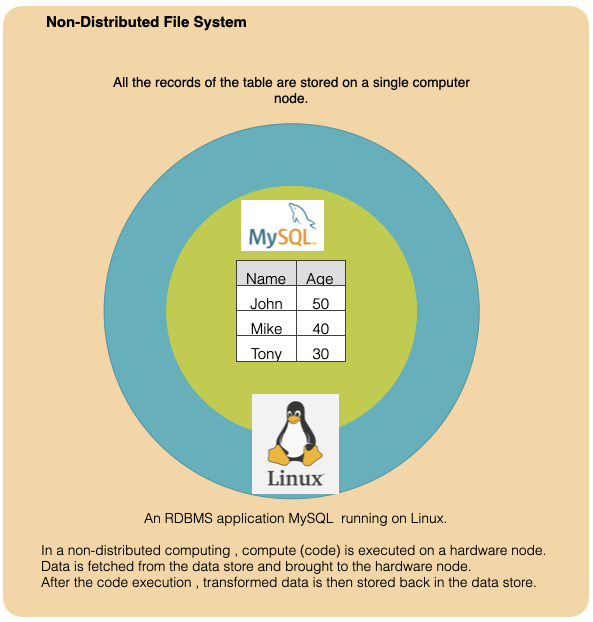
Having understood on how normal data is stored, let us look at how the same data is stored in a distributed data environment. Please note that distributed File System is required to store the data in distributed manner.
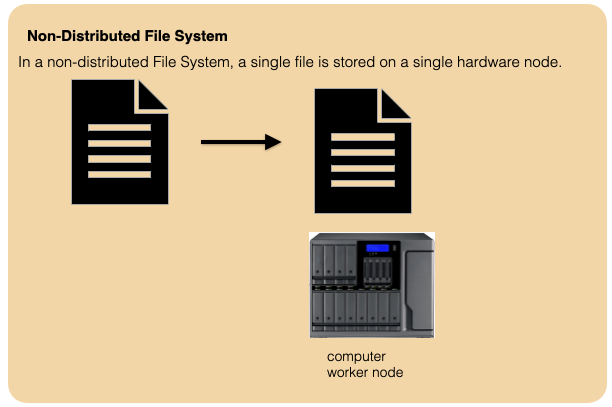
Lets take a moment to understand what a distributed File System is.
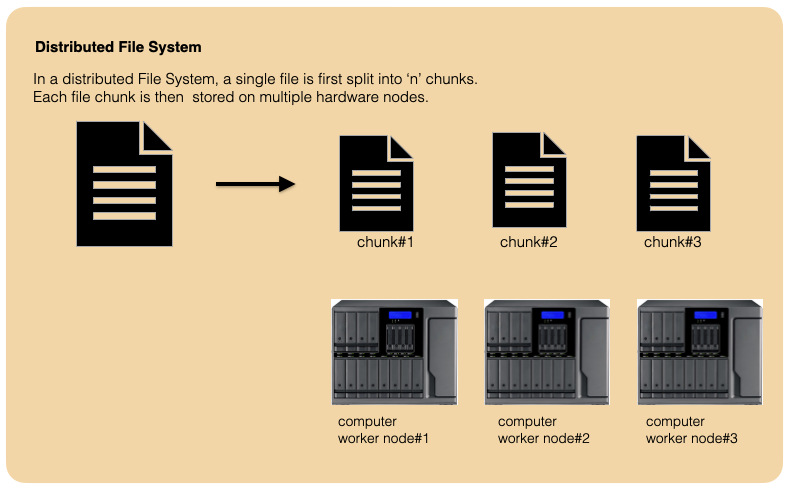
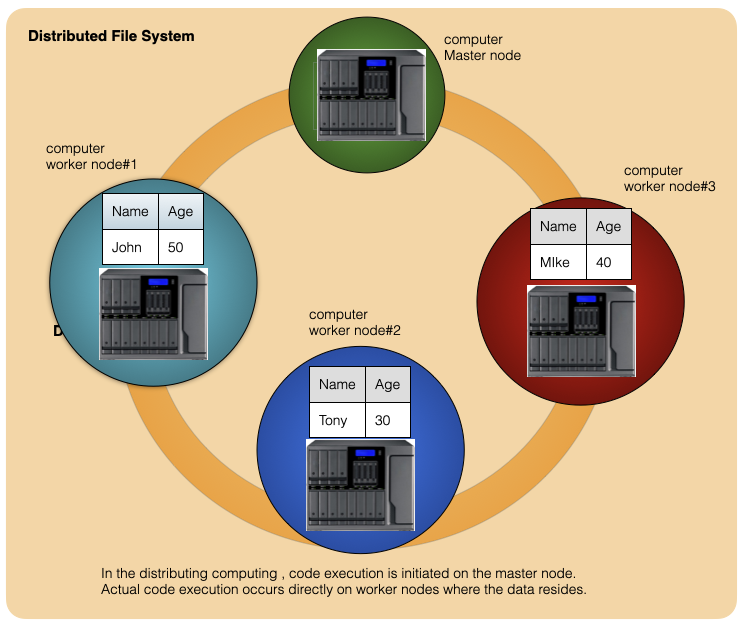
Below is an example of how data is distributed across 3 nodes. In this example, table consisting of 2 columns(Name & Age) and 3 rows are stored across 3 worker nodes . Each node stores one record. In spark, data operations are mostly carried out directly on a node where data resides instead of getting the data from other nodes.
3. Overview of Spark Cluster¶
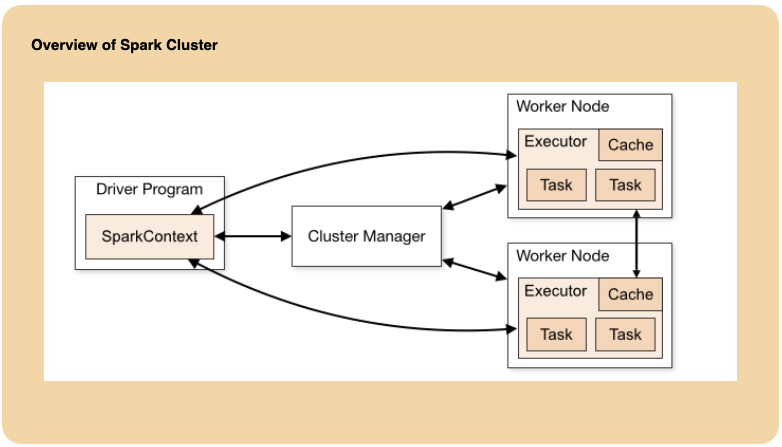
Spark uses a master/slave architecture. As you can see in the figure above, it has one central coordinator (Driver) that communicates with many distributed workers (executors). The driver and each of the executors run in their own Java processes.
DRIVER
The driver is the process where the main method runs. First it converts the user program into tasks and after that it schedules the tasks on the executors.
EXECUTORS
Executors are worker nodes’ processes in charge of running individual tasks in a given Spark job. They are launched at the beginning of a Spark application and typically run for the entire lifetime of an application. Once they have run the task they send the results to the driver. They also provide in-memory storage for RDDs that are cached by user programs through Block Manager.
APPLICATION EXECUTION FLOW
With this in mind, when you submit an application to the cluster with spark-submit this is what happens internally:
A standalone application starts and instantiates a SparkContext instance (and it is only then when you can call the application a driver).
The driver program ask for resources to the cluster manager to launch executors.
The cluster manager launches executors.
The driver process runs through the user application. Depending on the actions and transformations over RDDs task are sent to executors.
Executors run the tasks and save the results.
If any worker crashes, its tasks will be sent to different executors to be processed again. Spark automatically deals with failed or slow machines by re-executing failed or slow tasks. For example, if the node running a partition of a map() operation crashes, Spark will rerun it on another node; and even if the node does not crash but is simply much slower than other nodes, Spark can preemptively launch a “speculative” copy of the task on another node, and take its result if that finishes.
With SparkContext.stop() from the driver or if the main method exits/crashes all the executors will be terminated and the cluster resources will be released by the cluster manager.
4. How to create spark session?¶
import pyspark
from pyspark.sql import SparkSession
spark = SparkSession \
.builder \
.appName("Python Spark SQL basic example") \
.config("spark.some.config.option", "some-value") \
.getOrCreate()
You should see the following output to make sure spark session is working
spark
SparkSession - in-memory