

Chapter 12 : Null & NaN Column¶
Chapter Learning Objectives¶
Various data operations on Null & NaN columns.
Chapter Outline¶
import pyspark
from pyspark.sql import SparkSession
spark = SparkSession \
.builder \
.appName("Python Spark SQL basic example") \
.config("spark.some.config.option", "some-value") \
.getOrCreate()
from IPython.display import display_html
import pandas as pd
import numpy as np
def display_side_by_side(*args):
html_str=''
for df in args:
html_str+=df.to_html(index=False)
html_str+= "\xa0\xa0\xa0"*10
display_html(html_str.replace('table','table style="display:inline"'),raw=True)
space = "\xa0" * 10
import panel as pn
css = """
div.special_table + table, th, td {
border: 3px solid orange;
}
"""
pn.extension(raw_css=[css])
1a. How to count the Null & NaN in Spark DataFrame ?¶
Null values represents “no value” or “nothing” it’s not even an empty string or zero. A null value indicates a lack of a value
NaN stands for “Not a Number” It’s usually the result of a mathematical operation that doesn’t make sense, e.g. 0.0/0.0
Unlike Pandas, PySpark doesn’t consider NaN values to be NULL.

Input: Spark dataframe
df = spark.createDataFrame([(None, 3,float('nan')), (6,5, 2.0), (5,5, float("nan")),
(8, None, 2.0), (12,21,3.0),], ["a", "b","c"])
df.show()
+----+----+---+
| a| b| c|
+----+----+---+
|null| 3|NaN|
| 6| 5|2.0|
| 5| 5|NaN|
| 8|null|2.0|
| 12| 21|3.0|
+----+----+---+
df.printSchema()
root
|-- a: long (nullable = true)
|-- b: long (nullable = true)
|-- c: double (nullable = true)
Count of NaN in a Spark Data Frame
from pyspark.sql.functions import isnan, when, count, col
df.select([count(when(isnan(c), c)).alias(c) for c in df.columns]).show()
+---+---+---+
| a| b| c|
+---+---+---+
| 0| 0| 2|
+---+---+---+
Count of Null in a Spark Data Frame
df.select([count(when(col(c).isNull(), c)).alias(c) for c in df.columns]).show()
+---+---+---+
| a| b| c|
+---+---+---+
| 1| 1| 0|
+---+---+---+
Count of Null and NaN in a Spark Data Frame
df.select([count(when(isnan(c) | col(c).isNull(), c)).alias(c) for c in df.columns]).show()
+---+---+---+
| a| b| c|
+---+---+---+
| 1| 1| 2|
+---+---+---+
1b. How to filter the rows that contain NaN & Null?¶

Input: Spark dataframe containing JSON column
df = spark.createDataFrame([(None, 3,float('nan')), (6,5, 2.0), (5,5, float("nan")),
(8, None, 2.0), (12,21,3.0),], ["a", "b","c"])
df.show()
+----+----+---+
| a| b| c|
+----+----+---+
|null| 3|NaN|
| 6| 5|2.0|
| 5| 5|NaN|
| 8|null|2.0|
| 12| 21|3.0|
+----+----+---+
Learn to build the Boolean Expressions¶
from functools import reduce
filter_remove_nan_null_rows =reduce(lambda x, y: x & y, [~isnan(col(x)) for x in df.columns]+[col(x).isNotNull() for x in df.columns])
filter_remove_nan_null_rows
Column<b'((((((NOT isnan(a)) AND (NOT isnan(b))) AND (NOT isnan(c))) AND (a IS NOT NULL)) AND (b IS NOT NULL)) AND (c IS NOT NULL))'>
from functools import reduce
df.where(filter_remove_nan_null_rows).show()
+---+---+---+
| a| b| c|
+---+---+---+
| 6| 5|2.0|
| 12| 21|3.0|
+---+---+---+
df.where(~isnan(col("c")) & ~isnan(col("b"))).show()
+---+----+---+
| a| b| c|
+---+----+---+
| 6| 5|2.0|
| 8|null|2.0|
| 12| 21|3.0|
+---+----+---+
df.where(col("a").isNotNull()).show()
+---+----+---+
| a| b| c|
+---+----+---+
| 6| 5|2.0|
| 5| 5|NaN|
| 8|null|2.0|
| 12| 21|3.0|
+---+----+---+
df.where(col("a").isNull()).show()
+----+---+---+
| a| b| c|
+----+---+---+
|null| 3|NaN|
+----+---+---+
df.where(isnan(col("c"))).show()
+----+---+---+
| a| b| c|
+----+---+---+
|null| 3|NaN|
| 5| 5|NaN|
+----+---+---+
df.where(~isnan(col("c"))).show()
+---+----+---+
| a| b| c|
+---+----+---+
| 6| 5|2.0|
| 8|null|2.0|
| 12| 21|3.0|
+---+----+---+
Output : Spark dataframe containing individual JSON elements
1c. How to replace Null values in the dataframe?¶
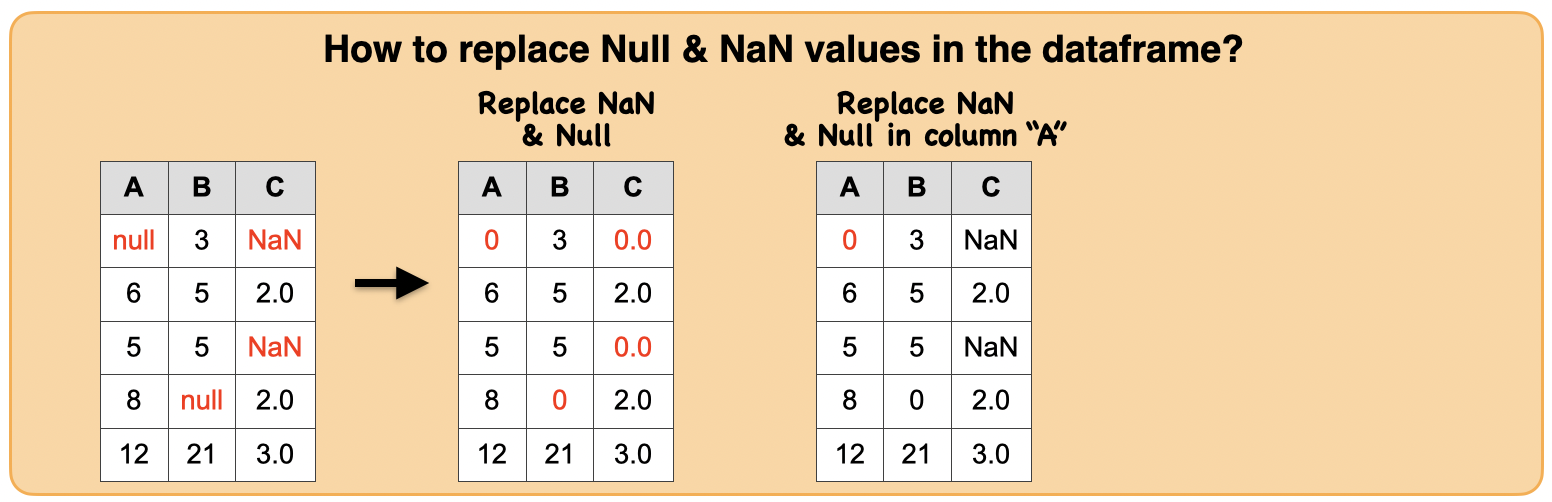
Input: Spark dataframe containing Null and NaN column
df = spark.createDataFrame([(None, 3,float('nan')), (6,5, 2.0), (5,5, float("nan")),
(8, None, 2.0), (12,21,3.0),], ["a", "b","c"])
df.show()
+----+----+---+
| a| b| c|
+----+----+---+
|null| 3|NaN|
| 6| 5|2.0|
| 5| 5|NaN|
| 8|null|2.0|
| 12| 21|3.0|
+----+----+---+
Output : Spark dataframe containing individual JSON elements
df.fillna(1000).show()
+----+----+------+
| a| b| c|
+----+----+------+
|1000| 3|1000.0|
| 6| 5| 2.0|
| 5| 5|1000.0|
| 8|1000| 2.0|
| 12| 21| 3.0|
+----+----+------+
Filling only for selected columns
df.fillna(1000,subset=["a"]).show()
+----+----+---+
| a| b| c|
+----+----+---+
|1000| 3|NaN|
| 6| 5|2.0|
| 5| 5|NaN|
| 8|null|2.0|
| 12| 21|3.0|
+----+----+---+
Filling with a different value for each of the Null Column
df.fillna(1000,subset=["a"]).fillna(500,subset=["b"]).show()
+----+---+---+
| a| b| c|
+----+---+---+
|1000| 3|NaN|
| 6| 5|2.0|
| 5| 5|NaN|
| 8|500|2.0|
| 12| 21|3.0|
+----+---+---+
Summary:
print("Input ", "Output")
print(" ", "Filling all columns"," ", "Filling selected columns"," ", "Filling a different value")
print(" ", "with a same value"," ", " " "for each column")
display_side_by_side(df.toPandas(),df.fillna(1000).toPandas(), df.fillna(1000,subset=["a"]).toPandas(),
df.fillna(1000,subset=["a"]).fillna(500,subset=["b"]).toPandas())
Input Output
Filling all columns Filling selected columns Filling a different value
with a same value for each column
| a | b | c |
|---|---|---|
| NaN | 3.0 | NaN |
| 6.0 | 5.0 | 2.0 |
| 5.0 | 5.0 | NaN |
| 8.0 | NaN | 2.0 |
| 12.0 | 21.0 | 3.0 |
| a | b | c |
|---|---|---|
| 1000 | 3 | 1000.0 |
| 6 | 5 | 2.0 |
| 5 | 5 | 1000.0 |
| 8 | 1000 | 2.0 |
| 12 | 21 | 3.0 |
| a | b | c |
|---|---|---|
| 1000 | 3.0 | NaN |
| 6 | 5.0 | 2.0 |
| 5 | 5.0 | NaN |
| 8 | NaN | 2.0 |
| 12 | 21.0 | 3.0 |
| a | b | c |
|---|---|---|
| 1000 | 3 | NaN |
| 6 | 5 | 2.0 |
| 5 | 5 | NaN |
| 8 | 500 | 2.0 |
| 12 | 21 | 3.0 |
1d. How to replace NaN values in the dataframe?¶
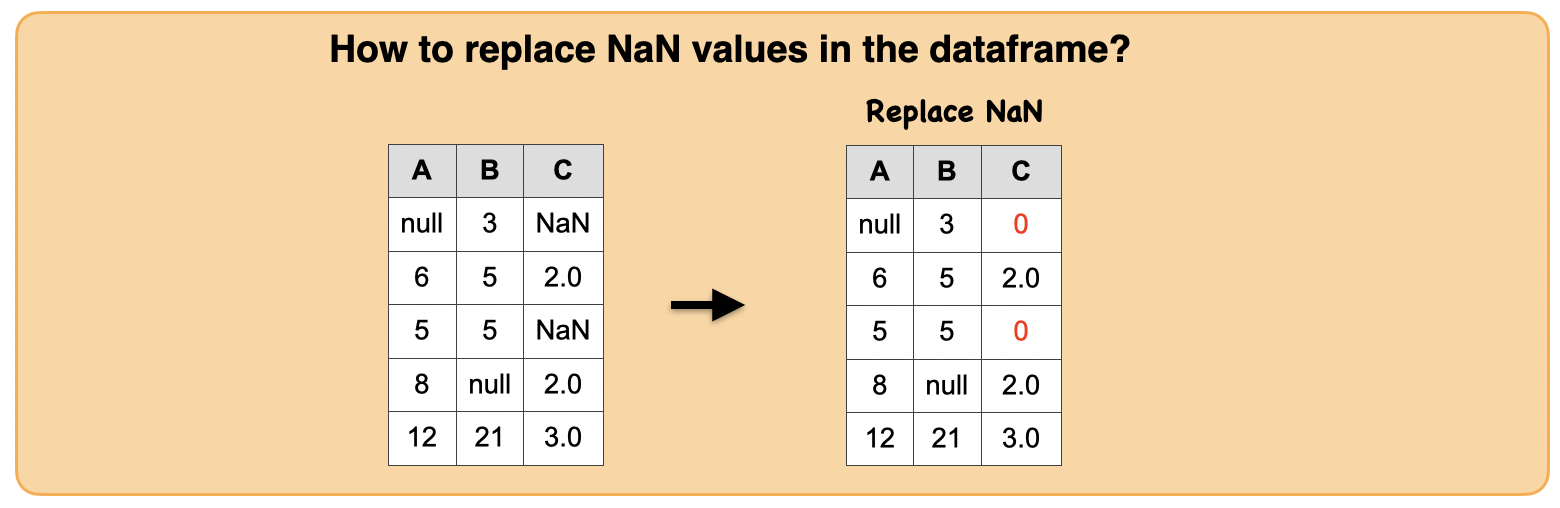
Input: Spark data frame
df = spark.createDataFrame([(None, 3,float('nan')), (6,5, 2.0), (5,5, float("nan")),
(8, None, 2.0), (12,21,3.0),], ["a", "b","c"])
df.show()
+----+----+---+
| a| b| c|
+----+----+---+
|null| 3|NaN|
| 6| 5|2.0|
| 5| 5|NaN|
| 8|null|2.0|
| 12| 21|3.0|
+----+----+---+
Output : Spark data frame with a struct column with a new element added
df.replace(float('nan'),10).show()
+----+----+----+
| a| b| c|
+----+----+----+
|null| 3|10.0|
| 6| 5| 2.0|
| 5| 5|10.0|
| 8|null| 2.0|
| 12| 21| 3.0|
+----+----+----+