

Chapter 9 : Map Column¶
Chapter Learning Objectives¶
Various data operations on columns containing map.
Chapter Outline¶
import pyspark
from pyspark.sql import SparkSession
spark = SparkSession \
.builder \
.appName("Python Spark SQL basic example") \
.config("spark.some.config.option", "some-value") \
.getOrCreate()
from IPython.display import display_html
import pandas as pd
import numpy as np
def display_side_by_side(*args):
html_str=''
for df in args:
html_str+=df.to_html(index=False)
html_str+= "\xa0\xa0\xa0"*10
display_html(html_str.replace('table','table style="display:inline"'),raw=True)
space = "\xa0" * 10
import panel as pn
css = """
div.special_table + table, th, td {
border: 3px solid orange;
}
"""
pn.extension(raw_css=[css])
1a. How to create a column of map type?¶
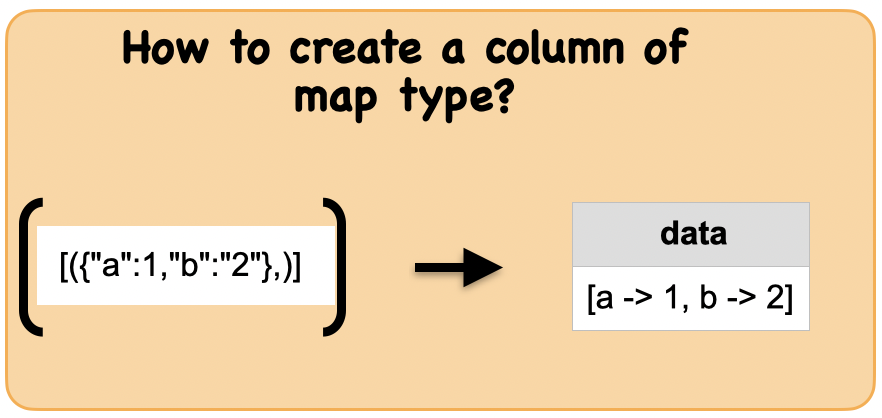
df = spark.createDataFrame([({"a":1,"b": 2,"c":3},)],["data"])
df.show(truncate=False)
print(df.dtypes)
+------------------------+
|data |
+------------------------+
|[a -> 1, b -> 2, c -> 3]|
+------------------------+
[('data', 'map<string,bigint>')]
1b. How to read individual elements of a map column ?¶

Input: Spark dataframe containing map column
df1 = spark.createDataFrame([({"a":1,"b": 2,"c":3},)],["data"])
df1.show(truncate=False)
+------------------------+
|data |
+------------------------+
|[a -> 1, b -> 2, c -> 3]|
+------------------------+
Output : Spark dataframe containing map keys as column and its value
df_map = df1.select(df1.data.a.alias("a"), df1.data.b.alias("b"), df1.data.c.alias("c") )
df_map.show()
+---+---+---+
| a| b| c|
+---+---+---+
| 1| 2| 3|
+---+---+---+
Summary:
print("Input ", "Output")
display_side_by_side(df1.toPandas(),df_map.toPandas())
Input Output
| data |
|---|
| {'a': 1, 'b': 2, 'c': 3} |
| a | b | c |
|---|---|---|
| 1 | 2 | 3 |
1c. How to extract the keys from a map column?¶
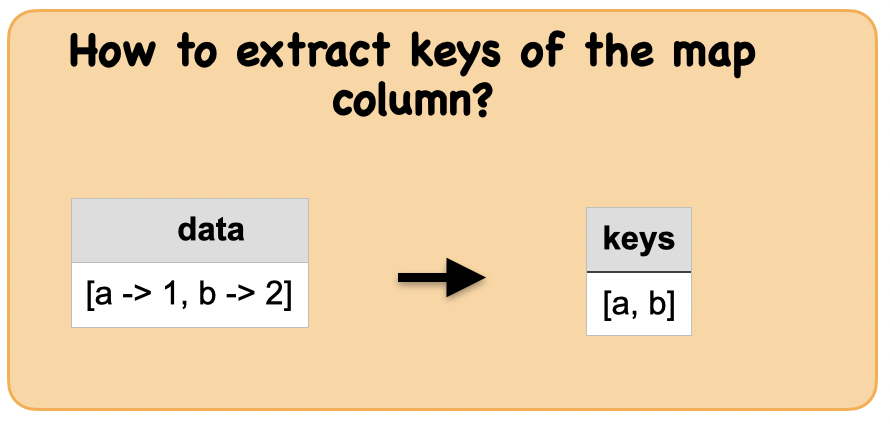
Lets first understand the syntax
Syntax
pyspark.sql.functions.map_keys(col)
Returns an unordered array containing the keys of the map.
Parameters:
col – name of column or expression
‘’’
Input: Spark data frame consisting of a map column
df2 = spark.createDataFrame([({"a":1,"b":"2","c":3},)],["data"])
df2.show(truncate=False)
+----------------------+
|data |
+----------------------+
|[a -> 1, b ->, c -> 3]|
+----------------------+
Output : Spark data frame consisting of a column of keys
from pyspark.sql.functions import map_keys
df_keys = df2.select(map_keys(df2.data).alias("keys"))
df_keys.show()
+---------+
| keys|
+---------+
|[a, b, c]|
+---------+
Summary:
print("input ", "output")
display_side_by_side(df2.toPandas(),df_keys.toPandas())
input output
| data |
|---|
| {'a': 1, 'b': None, 'c': 3} |
| keys |
|---|
| [a, b, c] |
1d. How to extract the values from a map column?¶

Lets first understand the syntax
Syntax
pyspark.sql.functions.map_values(col)
Collection function: Returns an unordered array containing the values of the map.
Parameters
col – name of column or expression
‘’’
Input: Spark data frame consisting of a map column
df3 = spark.createDataFrame([({"a":1,"b":"2","c":3},)],["data"])
df3.show(truncate=False)
+----------------------+
|data |
+----------------------+
|[a -> 1, b ->, c -> 3]|
+----------------------+
Output : Spark data frame consisting of a column of values
from pyspark.sql.functions import map_values
df_values = df3.select(map_values(df3.data).alias("values"))
df_values.show()
+-------+
| values|
+-------+
|[1,, 3]|
+-------+
Summary:
print("Input ", "Output")
display_side_by_side(df3.toPandas(),df_values.toPandas())
Input Output
| data |
|---|
| {'a': 1, 'b': None, 'c': 3} |
| values |
|---|
| [1, None, 3] |
1e. How to convert a map column into an array column?¶
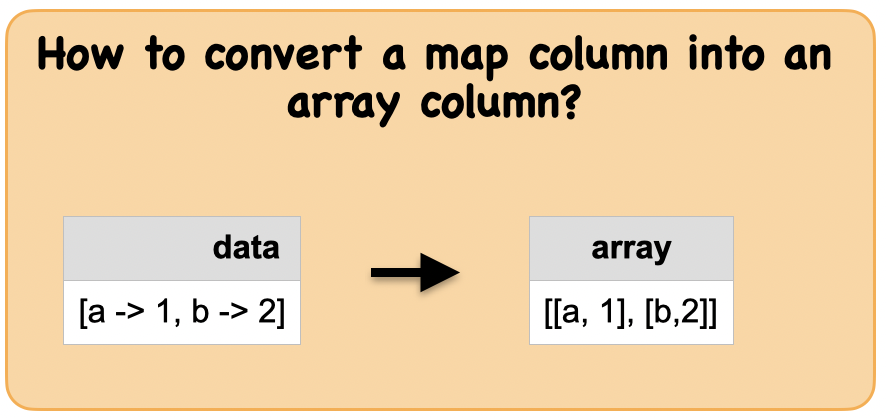
Lets first understand the syntax
Syntax
pyspark.sql.functions.map_entries(col)
Collection function: Returns an unordered array of all entries in the given map.
Parameters
col – name of column or expression ‘’’
Input: Spark data frame with map column
df4 = spark.createDataFrame([({"a":1,"b": 2,"c":3},)],["data"])
df4.show(truncate=False)
+------------------------+
|data |
+------------------------+
|[a -> 1, b -> 2, c -> 3]|
+------------------------+
Output : Spark dataframe containing an array
from pyspark.sql.functions import map_entries
df_array = df4.select(map_entries(df4.data).alias("array"))
df_array.show(truncate=False)
+------------------------+
|array |
+------------------------+
|[[a, 1], [b, 2], [c, 3]]|
+------------------------+
Summary:
print("Input ", "Output")
display_side_by_side(df4.toPandas(),df_array.toPandas())
Input Output
| data |
|---|
| {'a': 1, 'b': 2, 'c': 3} |
| array |
|---|
| [(a, 1), (b, 2), (c, 3)] |
1f. How to create a map column from multiple array columns?¶
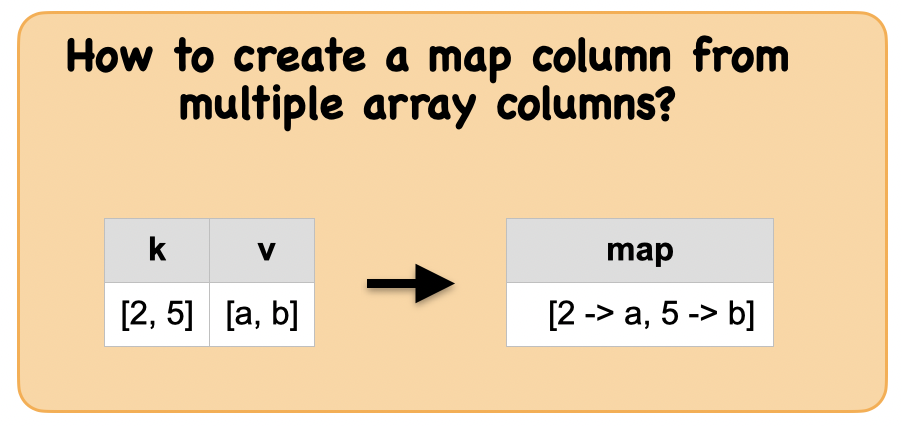
Lets first understand the syntax
Syntax
pyspark.sql.functions.map_from_arrays(col1, col2)
Creates a new map from two arrays.
Parameters
col1 – name of column containing a set of keys. All elements should not be null
col2 – name of column containing a set of values
‘’’
Input: Spark data frame with a column
df5 = spark.createDataFrame([([2, 5], ['a', 'b'])], ['k', 'v'])
df5.show()
+------+------+
| k| v|
+------+------+
|[2, 5]|[a, b]|
+------+------+
Output : Spark data frame with a column of array of repeated values
from pyspark.sql.functions import map_from_arrays
df_map1 = df5.select(map_from_arrays(df5.k, df5.v).alias("map"))
df_map1.show()
+----------------+
| map|
+----------------+
|[2 -> a, 5 -> b]|
+----------------+
Summary:
print("Input ", "Output")
display_side_by_side(df5.toPandas(),df_map1.toPandas())
Input Output
| k | v |
|---|---|
| [2, 5] | [a, b] |
| map |
|---|
| {5: 'b', 2: 'a'} |
1g. How to combine multiple map columns into one?¶
Lets first understand the syntax
Syntax
pyspark.sql.functions.map_concat(*cols)
Returns the union of all the given maps.
Parameters
col – name of columns
‘’’
Input: Spark data frame with multiple map columns
df6 = spark.sql("SELECT map(1, 'a', 2, 'b') as map1, map(3, 'c') as map2")
df6.show()
+----------------+--------+
| map1| map2|
+----------------+--------+
|[1 -> a, 2 -> b]|[3 -> c]|
+----------------+--------+
Output : Spark data frame with an array column with an element removed
from pyspark.sql.functions import map_concat
df_com = df6.select(map_concat("map1", "map2").alias("combined_map"))
df_com.show(truncate=False)
+------------------------+
|combined_map |
+------------------------+
|[1 -> a, 2 -> b, 3 -> c]|
+------------------------+
Summary:
print("Input ", "Output")
display_side_by_side(df6.toPandas(),df_com.toPandas())
Input Output
| map1 | map2 |
|---|---|
| {1: 'a', 2: 'b'} | {3: 'c'} |
| combined_map |
|---|
| {1: 'a', 2: 'b', 3: 'c'} |