

Chapter 10 : Struct Column¶
Chapter Learning Objectives¶
Various data operations on columns containing map.
Chapter Outline¶
import pyspark
from pyspark.sql import SparkSession
spark = SparkSession \
.builder \
.appName("Python Spark SQL basic example") \
.config("spark.some.config.option", "some-value") \
.getOrCreate()
from IPython.display import display_html
import pandas as pd
import numpy as np
def display_side_by_side(*args):
html_str=''
for df in args:
html_str+=df.to_html(index=False)
html_str+= "\xa0\xa0\xa0"*10
display_html(html_str.replace('table','table style="display:inline"'),raw=True)
space = "\xa0" * 10
import panel as pn
css = """
div.special_table + table, th, td {
border: 3px solid orange;
}
"""
pn.extension(raw_css=[css])
1a. How to create a struct column ?¶
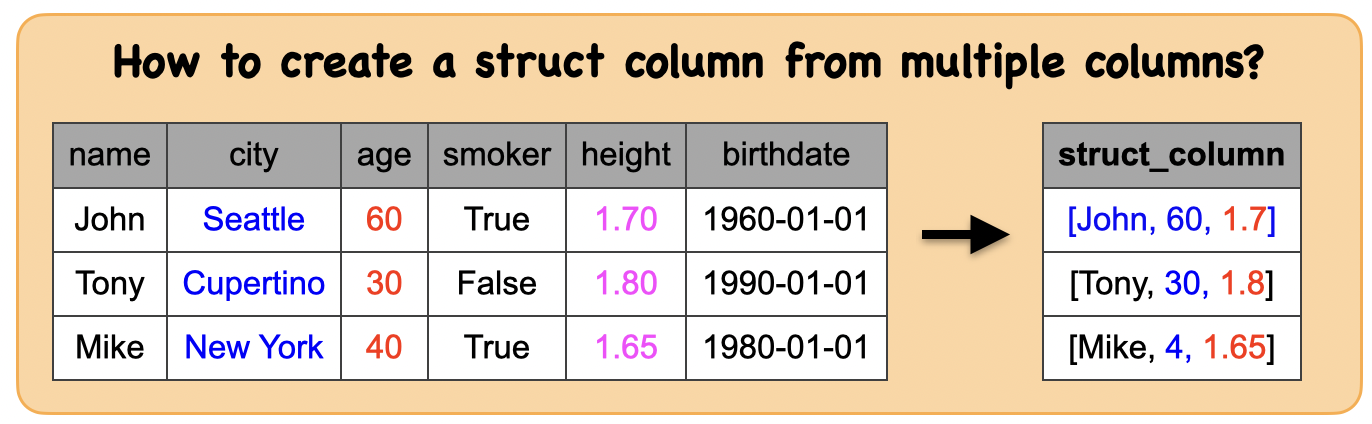
Input: Spark dataframe
df_mul = spark.createDataFrame([('John', 'Seattle', 60, True, 1.7, '1960-01-01'),
('Tony', 'Cupertino', 30, False, 1.8, '1990-01-01'),
('Mike', 'New York', 40, True, 1.65, '1980-01-01')],['name', 'city', 'age', 'smoker','height', 'birthdate'])
df_mul.show()
+----+---------+---+------+------+----------+
|name| city|age|smoker|height| birthdate|
+----+---------+---+------+------+----------+
|John| Seattle| 60| true| 1.7|1960-01-01|
|Tony|Cupertino| 30| false| 1.8|1990-01-01|
|Mike| New York| 40| true| 1.65|1980-01-01|
+----+---------+---+------+------+----------+
Output: Spark dataframe containing struct column
from pyspark.sql.functions import struct
df_stru = df_mul.select(struct(["name","age","height"]).alias("struct_column"))
df_stru.show()
+----------------+
| struct_column|
+----------------+
| [John, 60, 1.7]|
| [Tony, 30, 1.8]|
|[Mike, 40, 1.65]|
+----------------+
df_stru.dtypes
[('struct_column', 'struct<name:string,age:bigint,height:double>')]
1b. How to read individual elements of a struct column ?¶

Lets first understand the syntax
Syntax
getField(name)
An expression that gets a field by name in a StructField. ‘’’
Input: Spark dataframe containing struct column
df_stru = df_mul.select(struct(["name","age","height"]).alias("struct_column"))
df_stru.show()
+----------------+
| struct_column|
+----------------+
| [John, 60, 1.7]|
| [Tony, 30, 1.8]|
|[Mike, 40, 1.65]|
+----------------+
Output : Spark dataframe containing individual struct elements
df_ele = df_stru.select(df_stru.struct_column.getField("name").alias("name"), df_stru.struct_column.getField("age").alias("age"), df_stru.struct_column.getField("height").alias("height"))
df_ele.show()
+----+---+------+
|name|age|height|
+----+---+------+
|John| 60| 1.7|
|Tony| 30| 1.8|
|Mike| 40| 1.65|
+----+---+------+
Summary:
print("Input ", "Output")
display_side_by_side(df_stru.toPandas(),df_ele.toPandas())
Input Output
| struct_column |
|---|
| (John, 60, 1.7) |
| (Tony, 30, 1.8) |
| (Mike, 40, 1.65) |
| name | age | height |
|---|---|---|
| John | 60 | 1.70 |
| Tony | 30 | 1.80 |
| Mike | 40 | 1.65 |
1c. How to add new field to struct column?¶

Input: Spark data frame with a struct column
from pyspark.sql.functions import struct
df_mul = spark.createDataFrame([('John', 'Seattle', 60, True, 1.7, '1960-01-01'),
('Tony', 'Cupertino', 30, False, 1.8, '1990-01-01'),
('Mike', 'New York', 40, True, 1.65, '1980-01-01')],['name', 'city', 'age', 'smoker','height', 'birthdate'])
df_stru = df_mul.select(struct(["name","age","height"]).alias("struct_column"))
df_stru.show()
+----------------+
| struct_column|
+----------------+
| [John, 60, 1.7]|
| [Tony, 30, 1.8]|
|[Mike, 40, 1.65]|
+----------------+
Output : Spark data frame with a struct column with a new element added
df_stru_new = df_stru.withColumn("new",df_stru.struct_column.age+df_stru.struct_column.height )
df_stru_new = df_stru_new.select(struct("struct_column.name", "struct_column.age", df_stru_new.struct_column.height, "new").alias("struct_column"))
df_stru_new .show(3,False)
+-----------------------+
|struct_column |
+-----------------------+
|[John, 60, 1.7, 61.7] |
|[Tony, 30, 1.8, 31.8] |
|[Mike, 40, 1.65, 41.65]|
+-----------------------+
print(df_stru_new.schema)
StructType(List(StructField(struct_column,StructType(List(StructField(name,StringType,true),StructField(age,LongType,true),StructField(col3,DoubleType,true),StructField(new,DoubleType,true))),false)))
Summary:
print("input ", "output")
display_side_by_side(df_stru.toPandas(),df_stru_new.toPandas())
input output
| struct_column |
|---|
| (John, 60, 1.7) |
| (Tony, 30, 1.8) |
| (Mike, 40, 1.65) |
| struct_column |
|---|
| (John, 60, 1.7, 61.7) |
| (Tony, 30, 1.8, 31.8) |
| (Mike, 40, 1.65, 41.65) |
1d. How to drop field in struct column?¶

Input: Spark data frame with a struct column
from pyspark.sql.functions import struct
df_mul = spark.createDataFrame([('John', 'Seattle', 60, True, 1.7, '1960-01-01'),
('Tony', 'Cupertino', 30, False, 1.8, '1990-01-01'),
('Mike', 'New York', 40, True, 1.65, '1980-01-01')],['name', 'city', 'age', 'smoker','height', 'birthdate'])
df_stru = df_mul.select(struct(["name","age","height"]).alias("struct_column"))
df_stru.show()
+----------------+
| struct_column|
+----------------+
| [John, 60, 1.7]|
| [Tony, 30, 1.8]|
|[Mike, 40, 1.65]|
+----------------+
Output : Spark data frame with a struct column with an element deleted
df_stru_new = df_stru_new.select(struct("struct_column.name", "struct_column.age").alias("struct_column"))
df_stru_new .show(3,False)
+-------------+
|struct_column|
+-------------+
|[John, 60] |
|[Tony, 30] |
|[Mike, 40] |
+-------------+
Summary:
print("input ", "output")
display_side_by_side(df_stru.toPandas(),df_stru_new.toPandas())
input output
| struct_column |
|---|
| (John, 60, 1.7) |
| (Tony, 30, 1.8) |
| (Mike, 40, 1.65) |
| struct_column |
|---|
| (John, 60) |
| (Tony, 30) |
| (Mike, 40) |
1e. How to flatten a struct in a Spark dataframe?¶
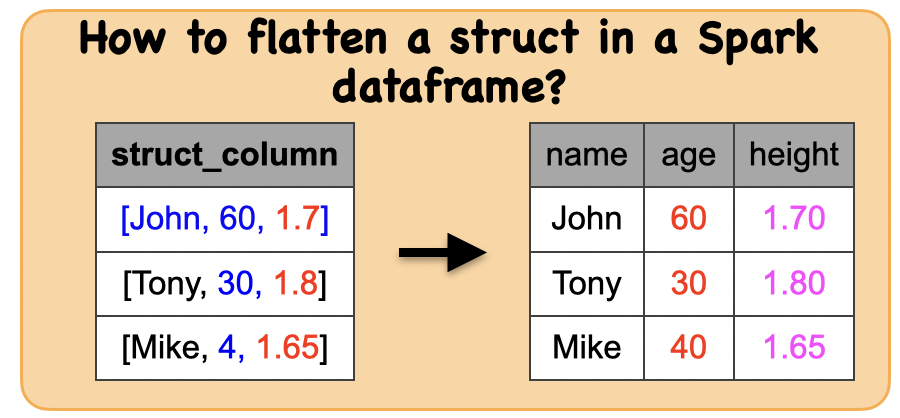
Input: Spark data frame with a struct column
from pyspark.sql.functions import struct
df_mul = spark.createDataFrame([('John', 'Seattle', 60, True, 1.7, '1960-01-01'),
('Tony', 'Cupertino', 30, False, 1.8, '1990-01-01'),
('Mike', 'New York', 40, True, 1.65, '1980-01-01')],['name', 'city', 'age', 'smoker','height', 'birthdate'])
df_stru = df_mul.select(struct(["name","age","height"]).alias("struct_column"))
df_stru.show()
+----------------+
| struct_column|
+----------------+
| [John, 60, 1.7]|
| [Tony, 30, 1.8]|
|[Mike, 40, 1.65]|
+----------------+
Output : Spark dataframe with flattened struct column
df_flat = df_stru.select("struct_column.*")
df_flat.show()
+----+---+------+
|name|age|height|
+----+---+------+
|John| 60| 1.7|
|Tony| 30| 1.8|
|Mike| 40| 1.65|
+----+---+------+
Summary:
print("Input ", "Output")
display_side_by_side(df_stru.toPandas(),df_flat.toPandas())
Input Output
| struct_column |
|---|
| (John, 60, 1.7) |
| (Tony, 30, 1.8) |
| (Mike, 40, 1.65) |
| name | age | height |
|---|---|---|
| John | 60 | 1.70 |
| Tony | 30 | 1.80 |
| Mike | 40 | 1.65 |